Welcome to pycvcam’s documentation!#
Description of the package#
Python Computer Vision Cameras transformations and models.
A computer vision camera is modeled by three main components:
Extrinsic: The transformation from the world coordinate system to the normalized camera coordinate system (
world_pointstonormalized_points)Distortion: The transformation from the normalized camera coordinate system to the distorted camera coordinate system (
normalized_pointstodistorted_points)Intrinsic: The transformation from the distorted camera coordinate system to the image coordinate system (
distorted_pointstoimage_points)
As described in the figure below, the package pycvcam uses the following notation:
world_points: The 3-D points \(\vec{X}_w\) with shape (…,3) expressed in the world coordinate system \((\vec{E}_x, \vec{E}_y, \vec{E}_z)\).normalized_points: The 2-D points \(\vec{x}_n\) with shape (…,2) expressed in the normalized camera coordinate system \((\vec{I}, \vec{J})\) with a unit distance along the optical axis \((\vec{K})\).distorted_points: The distorted 2-D points \(\vec{x}_d\) with shape (…,2) expressed in the normalized camera coordinate system \((\vec{I}, \vec{J})\) with a unit distance along the optical axis \((\vec{K})\).image_points: The 2-D points \(\vec{x}_i\) with shape (…,2) expressed in the image coordinate system \((\vec{e}_x, \vec{e}_y)\) in the sensor plane.pixel_points: The 2-D points \(\vec{x}_p\) with shape (…,2) expressed in the pixel coordinate system \((u, v)\) in the matrix of pixels.
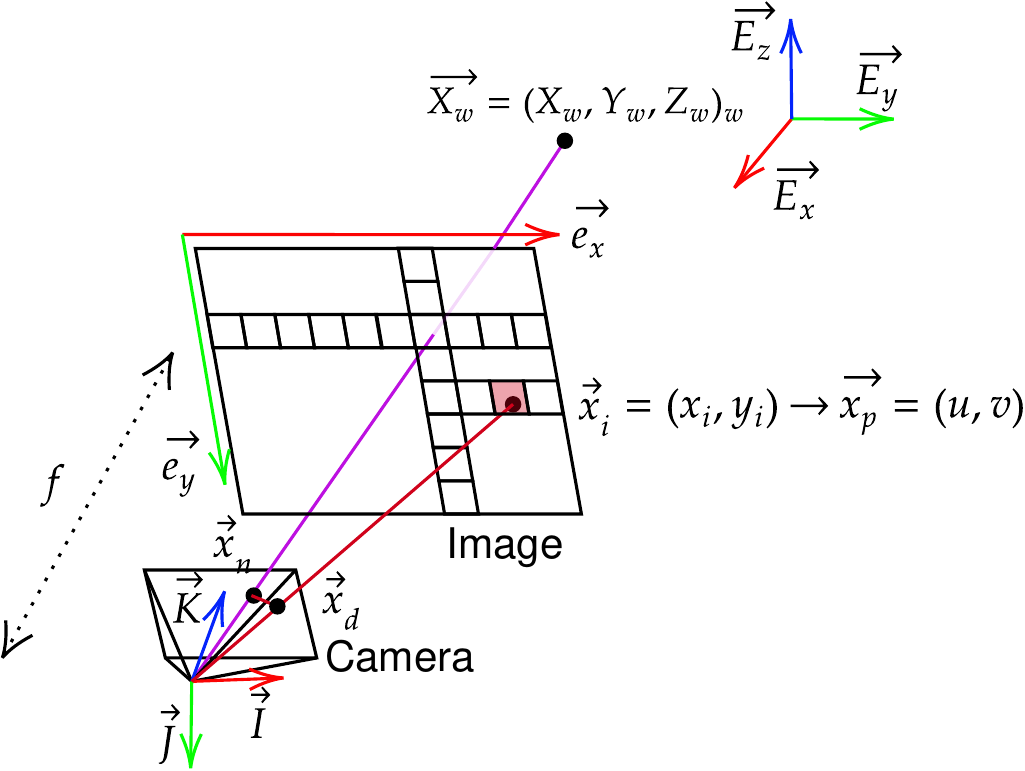
To convert the image_points to the pixel_points, a simple switch of coordinate system can be performed:
import numpy
import cv2
image = cv2.imread('image.jpg')
image_height, image_width = image.shape[:2]
pixel_points = numpy.indices((image_height, image_width), dtype=numpy.float64) # shape (2, H, W)
pixel_points = pixel_points.reshape(2, -1).T # shape (H*W, 2) WARNING: [H, W -> Y, X]
image_points = pixel_points[:, [1, 0]] # Swap to [X, Y] format
To model a camera without distortion (or intrinsic respectively), simply use an identity transformation.
These notations are used throughout the documentation.
Note
The package is designed to work with double-precision floating-point numbers to ensure numerical stability in all calculations.
Therefore, all float arrays are automatically converted to numpy.float64 for computation and all integer arrays are converted to numpy.int64 for computation.
This means that when you pass arrays to the functions in the package, they will be converted to these data types if they are not already in that format.
Contents#

Installation
This section describes how to install the package into a Python environment. It includes instructions for installing the package using pip, as well as any necessary dependencies.

API Reference
The reference guide contains a detailed description of the functions,
modules, and objects included in pycvcam. The reference describes how the
methods work and which parameters can be used. It assumes that you have an
understanding of the key concepts.

Examples Gallery
This section contains a collection of examples demonstrating how to use the package for various applications. Each example includes a description of the problem being solved, the code used to solve it, and the resulting output.
License#
Please refer to the [LICENSE] file for the license of the package.